Databricks is great tool and it make processing of large amount of data very easy. While designing Databricks workflow, I came across the need to reuse the logic and business rules across many notebooks. I do not want to create jar or python wheel as it will create dependency on another tool. My team primarily being consist of data engineers from SQL and ETL background, I don’t not want them to learn new things and they were also least interested going out of Databricks Notebook.
After research I came up with following solution to include the reusable logic from one notebook to another notebook.
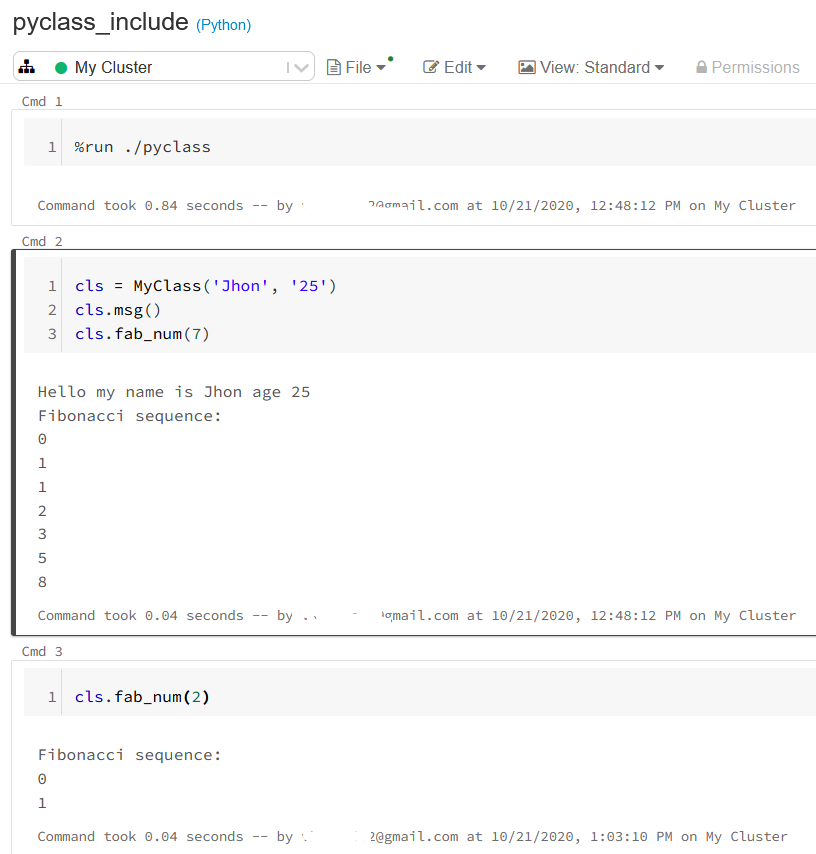
%run ./pyclass
Let me explain you in detail. I have created one notebook with python class including all the reusable logic and included that class in another notebook using %run magic command.
Once the class is included, I can simply create instance of the class and reuse it. In the example I created notebook name pyclass with class having two methods:
1. msg: displays message
2. fab_num : calculates Fibonacci numbers

In another notebook I created the instance of class and reused the logic.
Happy Coding!


